⚠️ ⚠️ ⚠️ Interrupção na AWS: o dia em que a nuvem parou — e o que aprender com isso ⚠️ ⚠️ ⚠️
Impactos reais, causas prováveis e um guia prático de resiliência para o seu negócio
Carlos Valente, em Outubro 20, 2025 | 187 visualizações | Tempo de leitura: 4 min - 733 palavras.

Quando a AWS sofre uma interrupção, o efeito dominó atinge milhares de empresas e milhões de usuários em minutos. O mais recente incidente mostrou que, mesmo com arquitetura de classe mundial, a concentração de cargas em uma única região e a falta de estratégias de resiliência podem transformar um “pequeno” evento técnico em um grande problema de negócio.
O que aconteceu e por que importa
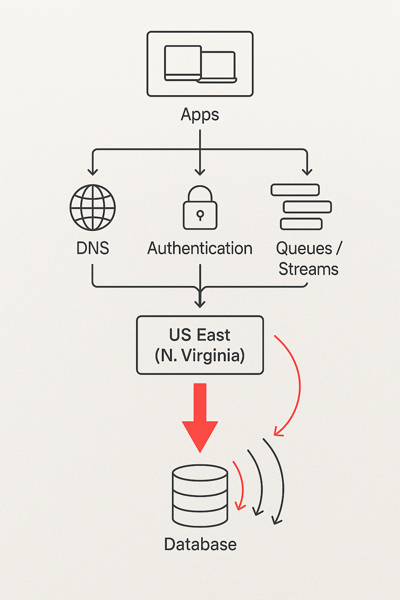
A interrupção mais recente afetou serviços amplamente usados — de aplicativos de mensagens e jogos a dispositivos conectados e plataformas corporativas — com origem em uma região crítica da AWS. Em poucas horas, vimos falhas encadeadas em autenticação, DNS, filas de dados, APIs internas e aplicativos que dependem de integrações em tempo real. Para o usuário final, “a internet caiu”; para as empresas, ficou claro o custo da indisponibilidade e da centralização.
Impactos mais frequentes durante uma interrupção
- Autenticação e login: falhas no IdP ou em caches/filas derrubam sessões, impedem renovações de token e travam checkouts.
- Dependências internas: serviços “backstage” (fila, stream, DNS interno, secrets) causam cascata de erros na borda.
- Observabilidade: sem métricas, logs e traces independentes, o time “voa às cegas” no pior momento.
- Suporte e comunicação: SLAs quebrados, filas cheias no atendimento e mensagens divergentes ao público.
6 lições aprendidas (com roteiro prático)
1) Projete para falhar bem (Failure-Oriented Design)
Adote o princípio de “failure domains”: limite o raio de impacto de cada componente. Desacople recursos por célula (cell-based), isole filas/streams críticos e defina timeouts, backoff exponencial e circuit breakers por padrão.
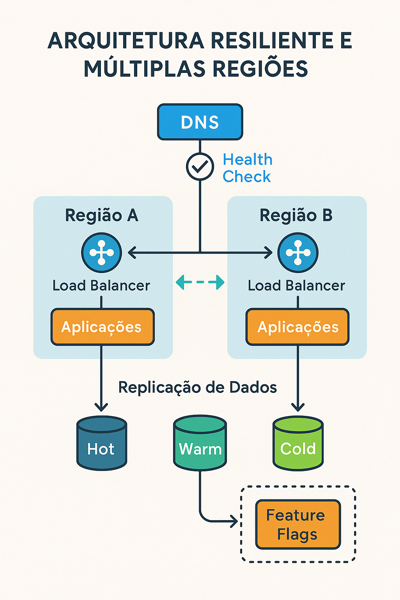
2) Multi-AZ é o mínimo; avalie Multi-Região para sistemas de frente
Alta disponibilidade intra-região reduz incidentes comuns, mas interrupções regionais exigem ativa-ativa ou ativa-passiva multi-região, com failover de DNS, replicação de dados, warm standby e readiness probes para “flip” automático e reversível.
3) Camada de DNS e roteamento como primeira classe
Configure políticas de DNS health checks e roteamento por latência/geo, mantenha TTLs coerentes com seu RTO e valide fallbacks (ex.: provedores diferentes para autoritativo/recursivo, quando aplicável).
4) Observabilidade independente
Métricas, logs e traces precisam sobreviver ao próprio incidente. Considere armazenar telemetria crítica fora da região primária (ou até fora do mesmo provedor), com painéis de “modo desastre” e alertas sintéticos batendo de fora para dentro.
5) Dados: consistência pragmática
Defina RPO e RTO por domínio. Nem tudo precisa de replicação síncrona entre regiões; use tiering: hot (síncrona) para cadastros/identidade, warm para transações, cold para relatórios. Evite “split-brain” com chaves de roteamento e idempotency keys.
6) Runbooks testados — e chaos engineering na veia
Runbooks não podem ser PDFs decorativos. Automatize: botão de failover, restauração de configurações, feature flags de degradação elegante (modo somente leitura, fila offline, queda de funcionalidades não essenciais). Valide tudo com game days e injeção de falhas.
Checklist de prontidão para o próximo incidente
- SLOs claros: defina SLO/SLI por jornada (login, checkout, upload) e publique o erro-budget.
- Mapeie dependências: catálogo de serviços com upstream/downstream e dados de criticidade.
- Degradação elegante: feature flags para “modo reduzido” sem travar todo o app.
- Planos de comunicação: status page, mensagens ao cliente e playbook de suporte alinhados.
- Testes programados: game days trimestrais (falha de região, DNS, filas, secrets).

Conclusão: resiliência é uma decisão contínua
Interrupções vão acontecer. A diferença entre um incidente contornável e uma crise generalizada está no design, na disciplina operacional e na prática deliberada. Comece pelos serviços mais críticos, implemente redundâncias inteligentes e treine a equipe. O investimento se paga no primeiro “dia ruim”.